Earlier this year NVIDIA made an announcement on a breakthrough in Embedded System-on-a-Chip (SoC) design with the Tegra K1. The diagram below outlines the Tegra K1 architecture.
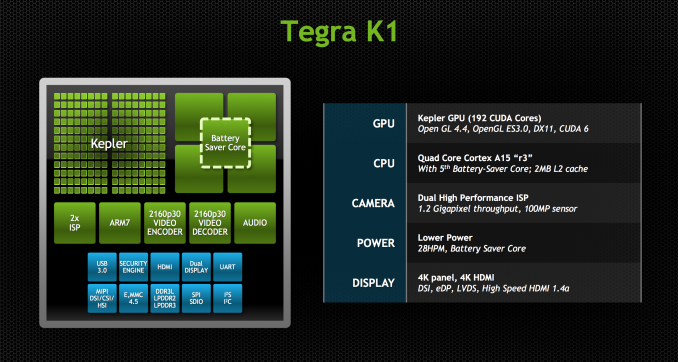
Obviously NVIDIA have an eye on the mobile gaming market, building on their Shield strategy, but equally recognise this step change in GFLOPS/W opens up major opportunities in the embedded market. This ranges from real-time vision and computation for autonomous cars, to advanced imaging applications for defence applications, UAVs in particular. In fact, General Electric Intelligent Platforms have signed a deal with NVIDIA to license the Tegra K1 SoC for their next generation embedded vehicle computing and avionics systems.
But, the really great thing about the Tegra K1 is that NVIDIA have released a development board call the Jetson K1, which retails for an amazing $192 in the US.
If you want to find out more detail on the Jetson K1, then I'd recommend visiting the Jetson page on eLinux.org.